核心数据结构¶
核心数据结构¶
涉及到的核心数据结构包括:区块、交易、UTXO、读写集。
区块¶
背景:所谓区块链,简单来说就是不同的区块以DAG方式链接起来形成的链。因此,区块是区块链的基本单元。
功能:区块是区块链的基本单元,通常为了提高区块链网络的吞吐,矿工会在一个区块中打包若干个交易。一个区块通常由区块头以及区块体组成。
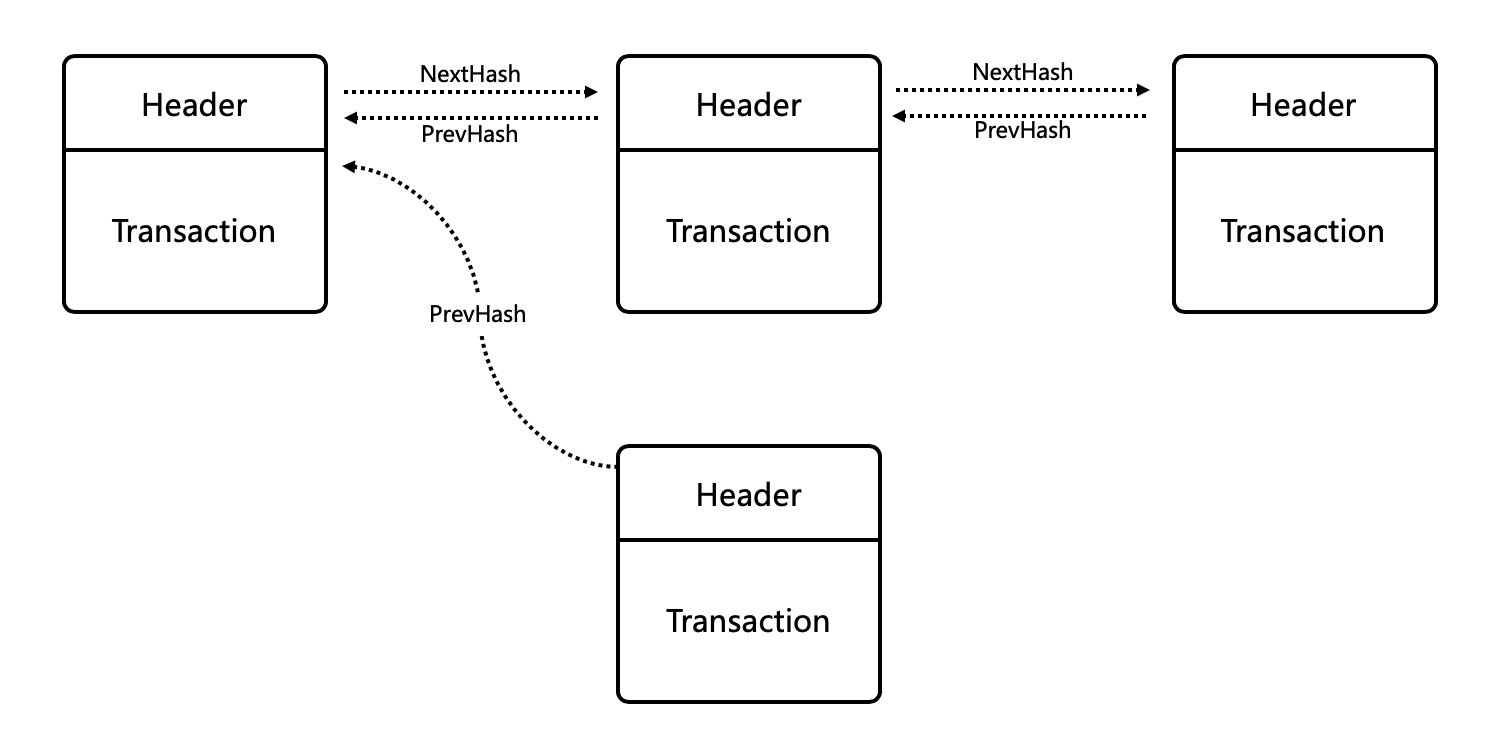
代码:区块的Proto如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | message InternalBlock {
// block version
// 区块版本
int32 version = 1;
// Random number used to avoid replay attacks
// 随机数,用来避免重放攻击
int32 nonce = 2;
// blockid generate the hash sign of the block used by sha256
// 区块的唯一标识
bytes blockid = 3;
// pre_hash is the parent blockid of the block
// 区块的前置依赖区块ID
bytes pre_hash = 4;
// The miner id
// 矿工ID
bytes proposer = 5;
// 矿工对区块的签名
// The sign which miner signed: blockid + nonce + timestamp
bytes sign = 6;
// The pk of the miner
// 矿工公钥
bytes pubkey = 7;
// The Merkle Tree root
// 默克尔树树根
bytes merkle_root = 8;
// The height of the blockchain
// 区块所在高度
int64 height = 9;
// Timestamp of the block
// 打包区块的时间戳
int64 timestamp = 10;
// Transactions of the block, only txid stored on kv, the detail information
// stored in another table
// 交易内容
repeated Transaction transactions = 11;
// The transaction count of the block
// 区块中包含的交易数量
int32 tx_count = 12;
// 所有交易hash的merkle tree
repeated bytes merkle_tree = 13;
// 采用DPOS共识算法时,当前是第几轮
int64 curTerm = 16;
int64 curBlockNum = 17;
// 区块中执行失败的交易以及对应的失败原因
map<string, string> failed_txs = 18; // txid -> failed reason
// 采用POW共识算法时,对应的挖矿难度值
int32 targetBits = 19;
// 下面的属性会动态变化
// If the block is on the trunk
// 该区块是否在主干上
bool in_trunk = 14;
// Next next block which on trunk
// 当前区块的后继区块ID
bytes next_hash = 15;
}
|
交易¶
背景:区块链网络中的每个节点都是一个状态机,为了给每个节点传递状态,系统引入了交易,作为区块链网络状态更改的最小操作单元。
功能:通常表现为普通转账以及智能合约调用。
代码:交易的Proto如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | message Transaction {
// txid is the id of this transaction
// 交易的唯一标识
bytes txid = 1;
// the blockid the transaction belong to
// 交易被打包在哪个区块中
bytes blockid = 2;
// Transaction input list
// UTXO来源
repeated TxInput tx_inputs = 3;
// Transaction output list
// UTXO去处
repeated TxOutput tx_outputs = 4;
// Transaction description or system contract
// 交易内容描述或系统合约
bytes desc = 6;
// Mining rewards
// 矿工奖励
bool coinbase = 7;
// Random number used to avoid replay attacks
// 随机数
string nonce = 8;
// Timestamp to launch the transaction
// 发起交易的时间戳
int64 timestamp = 9;
// tx format version; tx格式版本号
int32 version = 10;
// auto generated tx
// 该交易是否属于系统自动生成的交易
bool autogen = 11;
// 读写集中的读集
repeated TxInputExt tx_inputs_ext = 23;
// 读写集中的写集
repeated TxOutputExt tx_outputs_ext = 24;
// 该交易包含的合约调用请求
repeated InvokeRequest contract_requests = 25;
// 权限系统新增字段
// 交易发起者, 可以是一个Address或者一个Account
string initiator = 26;
// 交易发起需要被收集签名的AddressURL集合信息,包括用于utxo转账和用于合约调用
repeated string auth_require = 27;
// 交易发起者对交易元数据签名,签名的内容包括auth_require字段
repeated SignatureInfo initiator_signs = 28;
// 收集到的签名
repeated SignatureInfo auth_require_signs = 29;
// 节点收到tx的时间戳,不参与签名
int64 received_timestamp = 30;
// 统一签名(支持多重签名/环签名等,与initiator_signs/auth_require_signs不同时使用)
XuperSignature xuper_sign = 31;
}
|
UTXO¶
背景:区块链中比较常见的两种操作,包括普通转账以及合约调用,这两种操作都涉及到了数据状态的引用以及更新。为了描述普通转账涉及到的数据状态的引用以及更新,引入了UTXO(Unspent Transaction Output)。
功能:一种记账方式,用来描述普通转账时涉及到的数据状态的引用以及更新。通常由转账来源数据(UtxoInput)以及转账去处数据(UtxoOutput)组成。
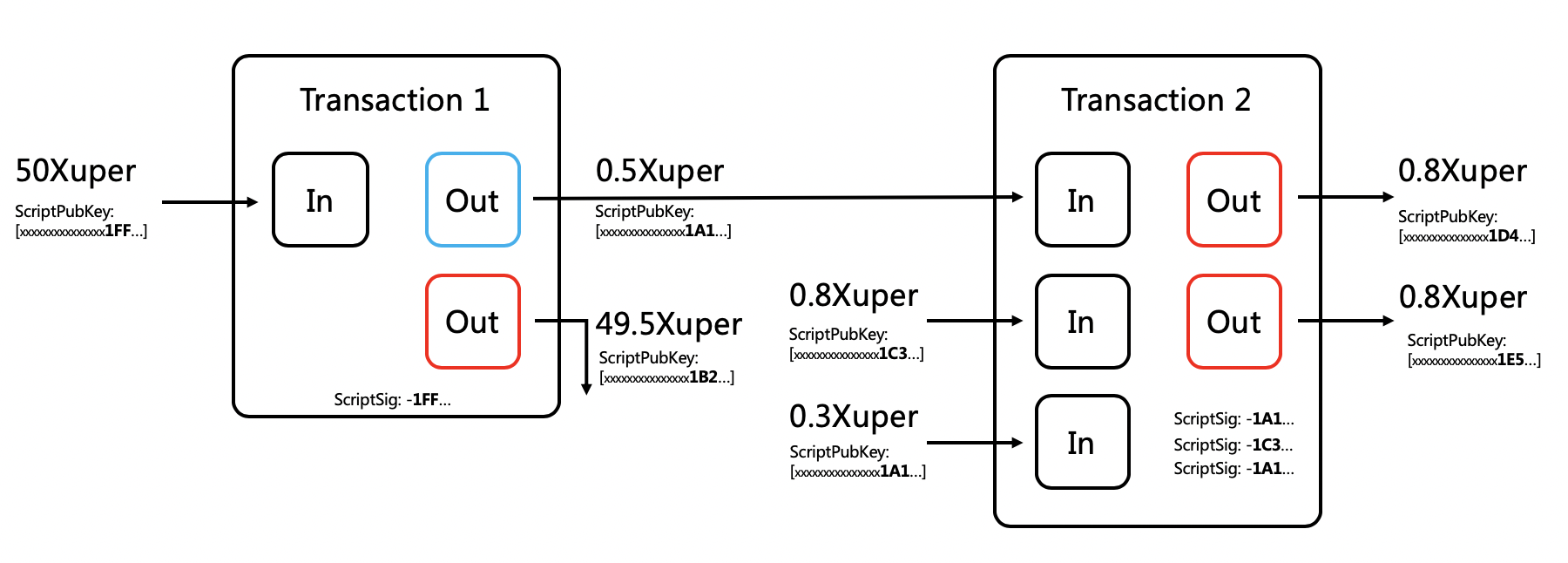
代码:UTXO的Proto如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | message Utxo {
// 转账数量
bytes amount = 1;
// 转给谁
bytes toAddr = 2;
// 转给谁的公钥
bytes toPubkey = 3;
// 该Utxo属于哪一个交易
bytes refTxid = 4;
// 该Utxo数据哪一个交易的哪一个offset
int32 refOffset = 5;
}
// UtxoInput query info to query utxos
// UTXO的转账来源
message UtxoInput {
Header header = 1;
// which bcname to select
// UTXO来源属于哪一条链
string bcname = 2;
// address to select
// UTXO来源属于哪个address
string address = 3;
// publickey of the address
// UTXO来源对应的公钥
string publickey = 4;
// totalNeed refer the total need utxos to select
// 需要的UTXO总额
string totalNeed = 5;
// userSign of input
// UTXO来源的签名
bytes userSign = 7;
// need lock
// 该UTXO是否需要锁定(内存级别锁定)
bool needLock = 8;
}
// UtxoOutput query results
// UTXO的转账去处
message UtxoOutput {
Header header = 1;
// utxo list
// UTXO去处
repeated Utxo utxoList = 2;
// total selected amount
// UTXO去处总额
string totalSelected = 3;
}
|
读写集¶
背景:区块链中比较常见的两种操作,包括普通转账以及合约调用,这两种操作都涉及到了数据状态的引用以及更新。为了描述合约调用涉及到的数据状态的引用以及更新,引入了读写集。
功能:一种用来描述合约调用时涉及到的数据状态的引用以及更新的技术。通常由读集(TxInputExt)以及写集(TxOutputExt)组成。
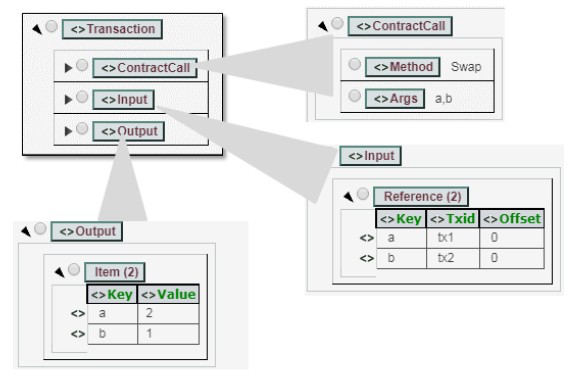
代码:读写集的Proto如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | // 扩展输入
message TxInputExt {
// 读集属于哪一个bucket
string bucket = 1;
// 读集对应的key
bytes key = 2;
// 读集属于哪一个txid
bytes ref_txid = 3;
// 读集属于哪一个txid的哪一个offset
int32 ref_offset = 4;
}
// 扩展输出
message TxOutputExt {
// 写集属于哪一个bucket
string bucket = 1;
// 写集对应的key
bytes key = 2;
// 写集对应的value
bytes value = 3;
}
|
XuperModel¶
XuperChain能够支持合约链内并行的很大的原因是由于其底层自研的XuperModel数据模型。
XuperModel是一个带版本的存储模型,支持读写集生成。该模型是比特币utxo模型的一个演变。在比特币的utxo模型中,每个交易都需要在输入字段中引用早期交易的输出,以证明资金来源。同样,在XuperModel中,每个事务读取的数据需要引用上一个事务写入的数据。在XuperModel中,事务的输入表示在执行智能合约期间读取的数据源,即事务的输出来源。事务的输出表示事务写入状态数据库的数据,这些数据在未来事务执行智能合约时将被引用,如下图所示:
XuperModel事务¶
为了在运行时获取合约的读写集,在预执行每个合约时XuperModel为其提供智能缓存。该缓存对状态数据库是只读的,它可以为合约的预执行生成读写集和结果。验证合约时,验证节点根据事务内容初始化缓存实例。节点将再次执行一次合约,但此时合约只能从读集读取数据。同样,写入数据也会在写入集中生效。当验证完生成的写集和事务携带的写集一致时合约验证通过,将事务写入账本,cache的原理如下所示,图中左边部分是合约预执行时的示意图,右边部分是合约验证时的示意图:
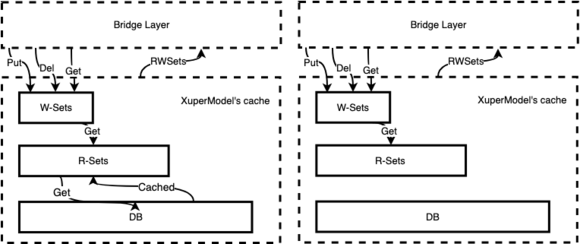
XuperModel合约验证¶
存储设计¶
背景¶
区块链中的账本数据通常是只增不减,而单盘存储容量有上限。目前单盘最高容量是14TB左右,需要花费4000块钱;以太坊账本数据已经超过1TB,即使是在区块大小上精打细算的比特币账本也有0.5TB左右。区块链账本数据不断增加,单盘容量上限成为区块链持续发展的天花板。 目前对leveldb的多盘扩展方案,大部分是采用了多个leveldb实例的方式,也就是每个盘一个单独的leveldb实例。这种做法的好处是简单,不需要修改leveldb底层代码,缺点是牺牲了多行原子写入的功能。在区块链的应用场景中,我们是需要这种多个写入操作原子性的。所以选择了改leveldb底层模型的技术路线。
LevelDB数据模型分析¶
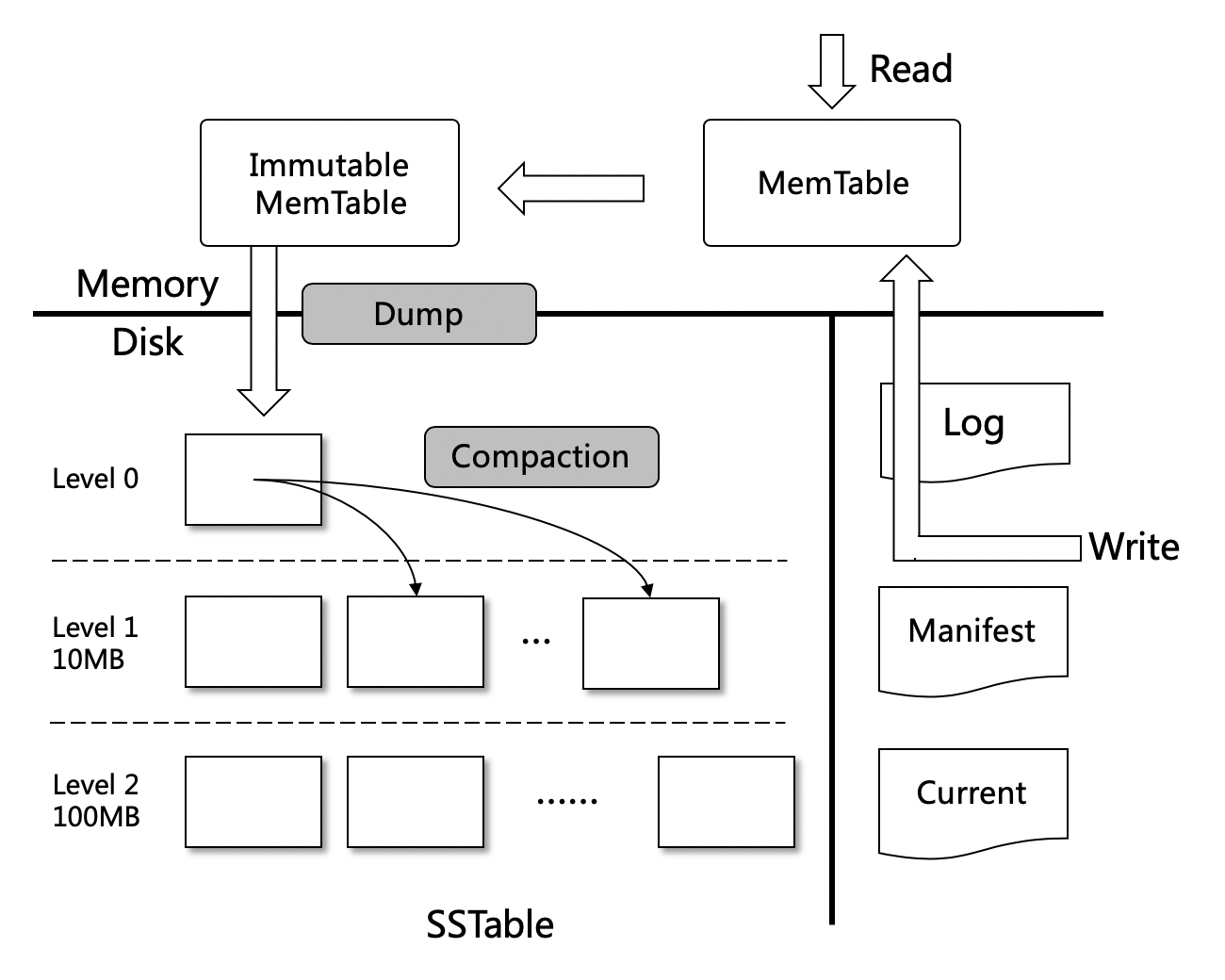
Log文件:写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
Manifest文件:Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息;
Current文件:LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名;
以上3种文件可以称之为元数据文件,它们占用的存储空间通常是几十MB,最多不会超过1GB
SST文件:磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;单个SST文件容量随层次增加成倍增长;文件内数据有序;其中Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
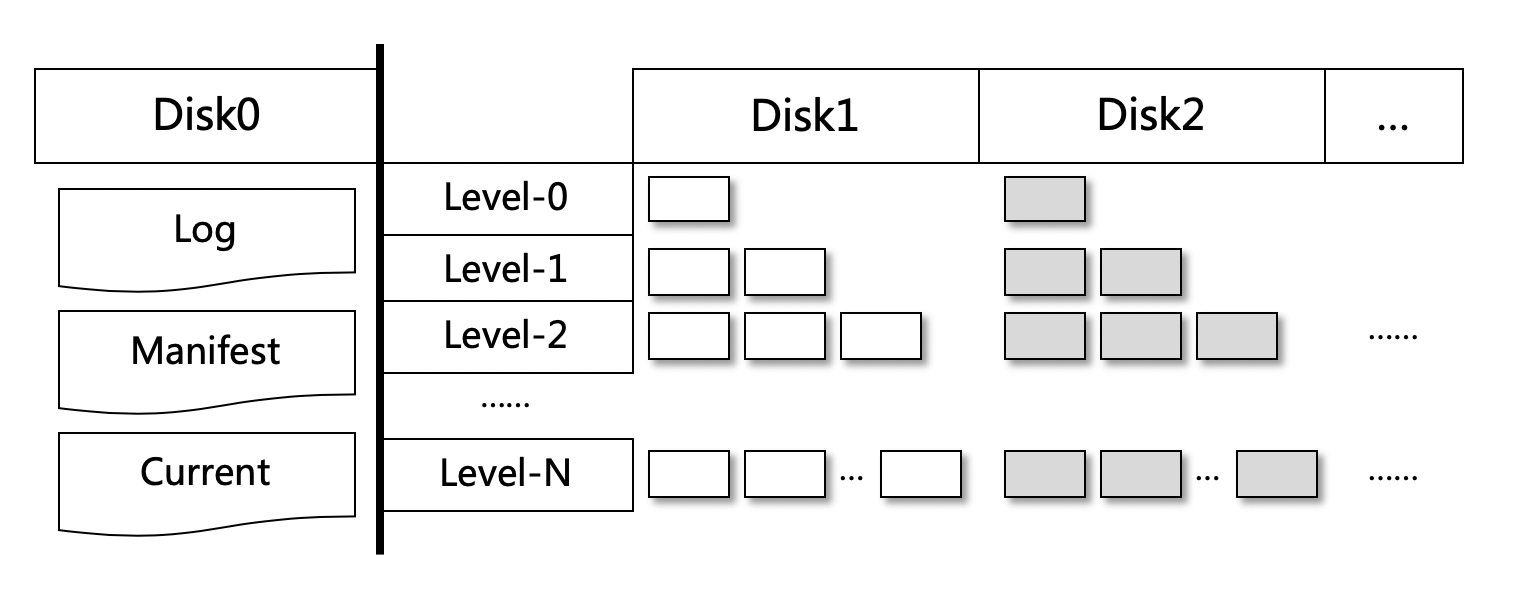
核心改造点¶
Leveldb的数据主要是存储在SST(Sorted String Table)文件中,写放大的产生就是由于compact的时候需要顺序读取Level-N中的sst文件,写出到Level-N+1的sst文件中。 我们将SST文件分散在多块盘上存储,具体的方法是根据sst的编号做取模散列,取模的底数是盘的个数, 理论上数据量和IO压力会均匀分散在多块盘上。
举个例子,假设某sst文件名是12345.ldb,而节点机器有3块盘用于存储(/disk1, /disk2, /disk3),那么就将改sst文件放置在 (12345 % 3) + 1, 也就是disk1盘上
使用方式¶
leveldb.OpenFile 有两个参数,一个是db文件夹路径path,一个是打开参数Options; 如果要使用多盘存储,调用者需要设置 Options.DataPaths 参数,它是一个[]string 数组,声明了各个盘的文件夹路径,可参考 配置多盘存储 。
扩容问题¶
假设本来是N块盘,扩容后是(N+M)块盘。对于已有的sst文件,因为取模的底数变了, 可能会出现按照原有的取模散列不命中的情况。 规则是:
对于读Open,先按照 (N+M) 取模去Open,如果不存在,则遍历各盘直到能Open到相应的文件,由于Open并不是频繁操作,代价可接受,且SST的编号是唯一且递增的,所以不存在读取脏数据的问题;
对于写Open,就按照 (N+M) 取模,因为写Open一定是生成新的文件。
随着Compact的不断进行,整个数据文件的分布会越来越趋向于均匀分布在 (N+M) 个盘,扩容完成。